Cassandra系列文章共四篇,本篇是第一篇。内容如下:
介绍
Apache Cassandra是一个开源、分布式、去中心化、弹性可伸缩、高可用、容错、可调一致性、面向行的数据库。它的分布式设计基于Amazon Dynamo,数据模型基于Google BigTable。Cassandra由Facebook创建,目前在Facebook、Twitter、Apple、360等各大IT企业成熟落地使用。
Cassandra最初是由Avinash Lakshman和Prashant Malik在Facebook开发的,用于支持收件箱搜索。Facebook于2008年将Cassandra开源作为Apache孵化器项目,并于2010年成为顶级Apache项目。
优势
- 大规模可扩展存储
Cassandra可扩展到数百TB,以出色的性能运行在商用集群上。 - 易于管理
Cassandra群集易于大规模管理,并且可以随需求的变化动态扩容。 - 高可用性
Cassandra设计为“持续在线”并已支持零停机时间升级等功能,应用于生产环境已有十多年的历史。 - 写密集型应用
Cassandra特别适合写密集型应用的时序型数据,如时间序列流数据、传感器日志数据和物联网应用程序等。 - 统计和分析
Cassandra支持与Spark等大数据计算框架集成,用户可以利用Spark强大的内存分析功能进行大数据统计和分析。 - 异地多活
Cassandra支持异地多数据中心,数据可以跨多个云和数据中心进行复制备份。
架构总览
集群架构
Cassandra集群由成节点(Node)、机架(Rack)和数据中心(Data Center)组成。
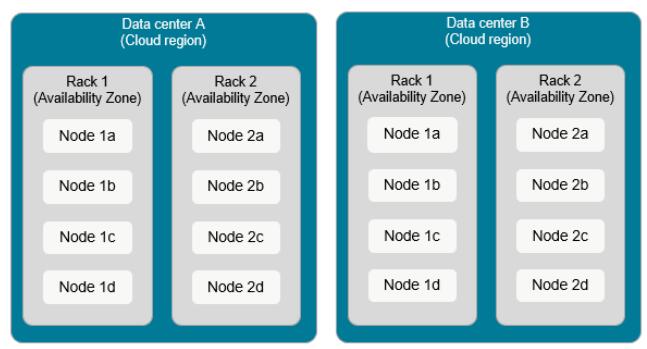
- 节点(Node)
指运行Cassandra实例的服务器。节点可以是物理主机、云上的机器实例,或者是Docker容器。 - 机架(Rack)
指一组相互靠近的Cassandra节点。机架可以是包含连接到公共网络交换机节点的物理机架。在云端,机架通常指在同一可用区域中运行机器实例集合。 - 数据中心(Data Center)
指逻辑机架的集合,通常位于同一栋建筑中,通过可靠的网络连接。在云端,数据中心通常映射到云区域。如阿里云上的华北1区,华南2区。
Cassandra通常跨多个数据中心存储数据副本,以确保高可用性,同时会将查询路由到同一数据中心的其他节点,以实现最优性能。为了实现这一点,Cassandra使用两个内部协议来管理基于集群拓扑的数据路由:gossip和snitches。
八卦协议(Gossip)
Gossip协议又被称为流行病协议(Epidemic Protocol),也叫反熵(Anti-Entropy),当前的新冠就是流行病协议的一个典型案例,为了方便记忆我们按字面意思叫它八卦协议。
Gossip协议于1987年在ACM上发表的论文 《Epidemic Algorithms for Replicated Database Maintenance》中被提出,有兴趣可以读一下原文(搞架构啃论文是绕不过的坎儿)。主要用在分布式数据库系统中各个副本节点间的数据同步,这种场景的一个最大特点就是组成网络的节点都是对等的,网络中即使有的节点因宕机而重启,或有新节点加入,但经过一段时间后,这些节点的状态也会与其他节点达成一致,也就是说,Gossip天然具有分布式容错的优点。它是一个带冗余的容错算法,属于一种最终一致性算法。虽然无法保证在某个时刻所有节点状态一致,但可以保证在”最终“所有节点一致,”最终“是一个现实中存在,但理论上无法证明的时间点。

Cassandra中的Gossip协议允许每个节点跟踪群集中其他节点的状态。每个Cassandra实例中的“ Gossiper”每秒运行一次,并最多选择三个随机节点来发起gossip会话。节点之间相互交换有关其他节点的信息,以便所有节点快速了解整个群集状态。 Cassandra会根据Gossip会话是否可以连接来确定节点是运行状态还是关闭状态,从而帮助其在集群中优化路由请求。
告密者(Snitches)
在Cassandra中请求路由的另一个关键技术是“Snitch”。 翻译成中文是告密者,就像语义一样,告密者的工作是通知每个节点与其他节点的相对距离。 此信息用于确定从哪些节点读取和写入,以及在节点出现故障或无法访问机架或数据中心时如何以最优路径分发副本以最大限度地提高可用性。
Cassandra有多种类型的告密者实现。大多数环境中推荐使用“GossipingPropertyFileSnitch”。Cassandra还提供了针对多种公有云环境优化的告密者。例如,当部署跨越阿里云区域的Cassandra集群时,用户可以选择“AlibabaCloudSnitch”。
可以在源代码org.apache.cassandra.locator包中找到这些snitch。每个snitch都实现了IEndpointSnitch接口。你可以根据特定需求实现自己的Snitch类。
Cassandra不仅提供了可插拔的方式来静态定义集群拓扑结构,它还提供了一种动态snitch的特性,可以帮助优化读写操作的路由。其实现为DynamicEndpointSnitch类。它会得到集群的基本拓扑信息,然后检测各节点请求的性能,甚至会跟踪哪些节点完成合并等性能指标。这些性能数据会用来为每个查询选择最适合的副本。这就可以避免Cassandra把请求路由到性能不佳的副本。
动态snitch实现使用了Phi故障检测机制算法。Phi累积性故障检测(Phi Accrual Failure Detection),简单说是一种用线性表示可信度级别的算法。比如我们开发监控平台,检测服务的健康程度,如果只是用端口是否正常、进程是否存活来判断服务的健康程度是不科学的,服务的健康程度不是非活即死,它还会有中间状态。累积型故障检测器会输出与各个进程(或节点)关联的一个值。这个值称为Phi。输出这个值的设计初衷是为了适应易变的网络状况,所以这不是一个二态性条件,不是只检测服务期是否宕机。好吧,想搞明白这个算法,那就继续read fucking paper《The ϕ Accrual Failure Detector》。
动态snitch是一个Phi的修改版本。有一个参数叫“糟糕度阈值”(badness threshold),用来确定一个优先节点必须必表现最好的节点糟糕多少才会失去优先地位。每个节点的糟糕度分数会定期重置,使得表现不好的节点有机会表明它已修复,并要求恢复其优先地位。
环结构和令牌
节点、机架和数据中心描述Cassandra集群的物理部署方式,“环”的概念通常用于解释数据的逻辑组织方式。Cassandra将一个集群管理的数据表示为环。会为环中的每个节点分配一个或多个数据区间或范围,由一个令牌描述,确定数据在环中的位置。
Cassandra查询语言(CQL)很像SQL,易于学习。以车联网中存储历史轨迹的gps表为例。一个“gps”的表包含每个设备上传的历史定位信息。我们可以使用以下CQL命令创建一个表:
1 | CREATE TABLE gps ( |
为了确定数据的存储位置,对分区键(示例中为device_id)进行哈希处理以确定令牌。 令牌是一个64位整数型ID,范围从-2^63到+2^63,用于标识每个分区。令牌值确定数据将驻留在哪个Cassandra节点上。也就是说每个设备采集的所有历史轨迹点在一个分区中。
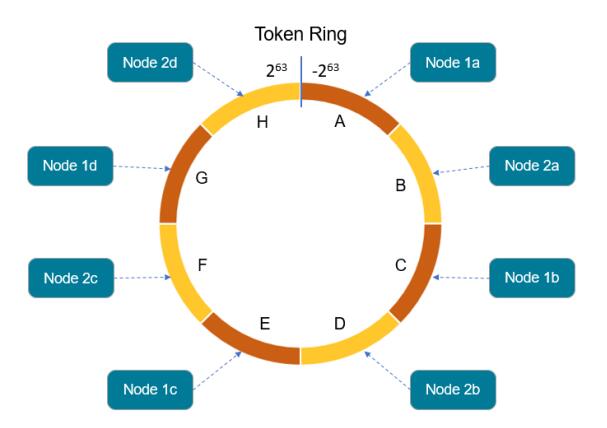
上图所示的环中的每个Cassandra节点都分配了一系列令牌值。 在早期版本的Cassandra(1.2版之前)中,令牌范围是手动分配给节点的。 一个节点拥有小于等于该节点令牌且大于前一个节点令牌的值区间。 该示例说明了一个集群的环形布局,该集群由具有单个数据中心的两个机架组成。 该排列的结构使得连续的令牌范围分布在不同机架中的节点上。
最新版本的Cassandra支持虚拟节点的概念,即vnode,其中每个Cassandra节点支持分布在整个令牌环中的多个令牌范围。每个主机的vnode数量是可配置的。vnode使Cassandra更容易管理,因为令牌范围的生成和分配是自动处理的。
看到这有些同学可能会注意到,这不就是一致性哈希算法吗。好吧,又是一个常用的分布式算法,不过这个算法相对来说比较简单,可以自行百度学习。
Cassandra的nodetool status命令可提供有关令牌范围管理方式的可见性。如下面的例子,Cassandra集群的三节点部署在同一个数据中心的同一个机架上运行。 使用了“GossipingPropertyFileSnitch”,因此数据中心名称映射为dc1,机架映射到可用性区域(rack1)。 在此示例中,每个Cassandra节点管理256个令牌,并且每个令牌定义一个令牌范围。 三节点集群为Keyspace(可理解为传统数据库的库)配置了两个复制因子,因此每个节点大约拥有逻辑环的三分之二。
1 | Datacenter: dc1 |
总结
我们主要梳理了Cassandra的集群架构技术,Cassandra集群物理结构由节点、机架、数据中心组成。使用Gossip协议实现了无中心架构架构。使用Snitch机制实现了节点感知以提高性能。使用环结构和令牌机制实现了集群的动态扩容和数据分区。
我们还在分析架构过程中分析了三种分布式系统中常用算法:Gossip、Phi、一致性哈希。

