Cassandra系列文章共四篇,本篇是第二篇。内容如下:
查询与集群复制
在Cassandra中,客户端可以是运行CQL命令的用户,也可以是使用不同语言Cassandra驱动连接到Cassandra的系统。Cassandra的无中心架构的主要优点之一是客户端可以连接到任意Cassandra节点。Cassandra驱动实现了负载均衡功能,可以跨节点分发客户端请求。客户端连接到的节点称为协调器。
协调器负责与其他节点交互,收集结果,并将查询结果返回给客户端,如下图所示。为了确保即使节点发生故障或无法访问,Cassandra也可以跨多个节点存储冗余数据,具体取决于创建Keyspace时指定的复制因子。
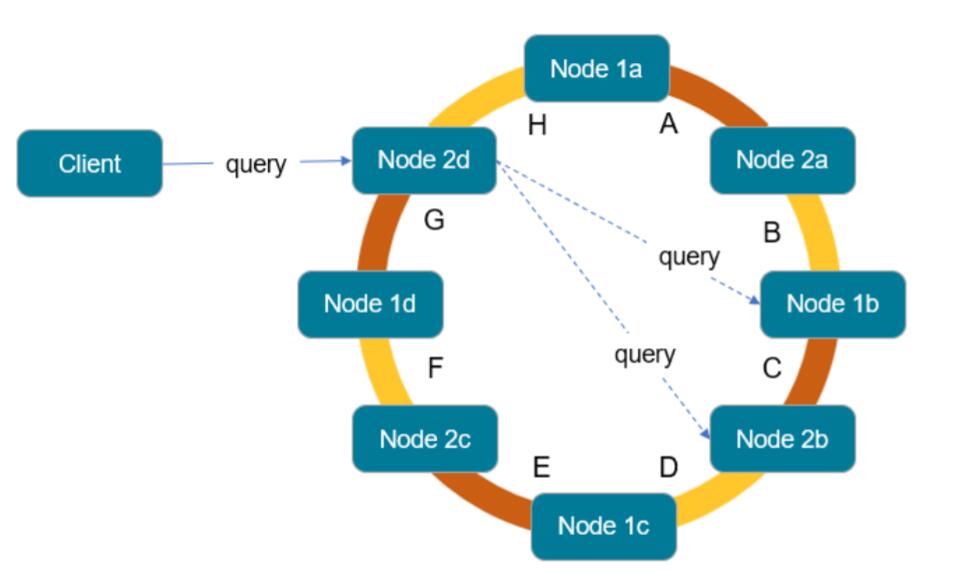
Cassandra考虑了集群的拓扑结构,并尝试在适当的情况下跨机架和数据中心(或公有云区域)分布数据。 分区键(partition key)确定集群中哪些节点保存副本。
可调一致性
提到分布式架构,就不得不提CAP理论,即一致性、可用性和分区容错性。在分布式数据库中,必须在AP和CP间做出选择。因为在分布式数据库中,更新数据需要跨网络传输到远程集群节点。与可以保证强一致性(以性能和可扩展性为代价)的RDBMS不同,分布式数据库通常是“最终一致的”。 Cassandra一个被低估的特性就是它提供了可调一致性,允许开发者在数据一致性和可用性之间的做出权衡。并且这种灵活性由客户端来管理。一致性可以全局的,也可以针对单个读取和写入操作进行调整。例如在更新重要数据(如财务帐户余额)时,将需要高度的一致性。 对于不太关键的应用或服务中,如电商网站显示某商品的客户评论数量,可以放宽一致性以实现更好的性能。
写一致性
对于写操作,一致性级别指定必须有多少个副本节点响应这个写操作才能向客户端响应这是一个成功的写操作。更高的写一致性级别可能带来可用性的下降,因为必须有更多的节点响应写操作才能成功。下图是Cassandra提供的写一致性级别。
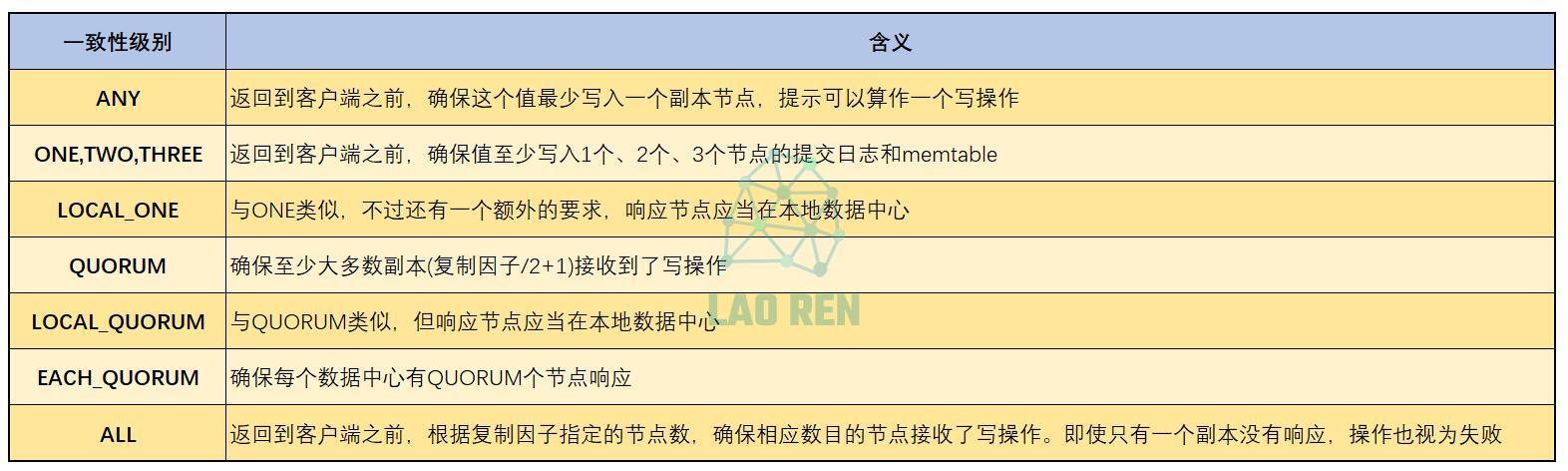
ANY这个级别意味着如果要完成一个写操作,而写这个值的目标节点宕机,服务器会自己做一个记录,这称为一个提示,这个提示会一直保存到节点恢复。一旦节点重新上线,正常节点会检测到它已经恢复,查看是否有需要完成的写操作,然后把值写入复活的节点。
当使用驱动程序作为客户端访问服务器时,如果设置为ANY并且遇到上面的情况,客户端会报出以下异常信息,但会正常执行。
1 | com.datastax.driver.core.exceptions.NoHostAvailableException: All host(s) tried for query failed (tried: |
如果使用ONE作为写一致性级别,即使集群中只有一个节点没有宕机,客户端也会正常写入返回,而不会报出异常。
代码实现
使用DataStax Java驱动程序中,可以提供一个com.datastax.driver.core.QueryOptions对象在Cluster.Builder上设置默认一致性级别:
1 | QueryOptions queryOptions = new QueryOptions(); |
也可以在单个语句上覆盖默认一致性级别:
1 | Statement statement = ... |
如果使用Spring Data for Apache Cassandra实现,全局设定可以在配置文件中添加:
1 | =quorum |
单个语句可以在代码中加入注解:
1 | (ConsistencyLevel.LOCAL_ONE) |
如果使用CassandraTemplate,也可以按以下方式设定:
1 | cassandraTemplate.insert(myEntity, new WriteOptions().builder() |
读一致性
对于读操作,一致性级别指定了返回数据之前必须有多少个副本节点响应这个读查询;
如果两个节点响应时有不同的时间戳,会采用最新的值,将这个值返回给客户端。然后Cassandra会在后台完成读修复:它会用最新的值去更新过期副本的值,使集群数据一致。
读一致性级别如下图:
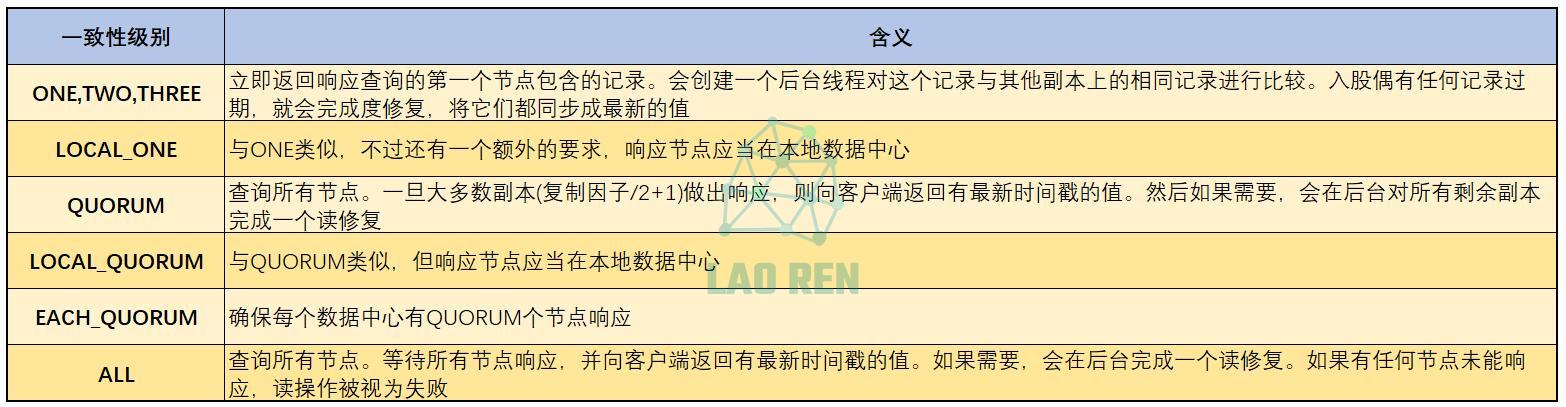
读操作不支持ANY一致性级别。ONE一致性级别的含义是客户端会得到读操作的第一个节点的值,即使这个值是过期的。读修复操作会在返回这个记录之后异步完成,使得所有后续读操作都有一致性的值,而无论哪一个是响应节点。
配置文件中的rpc_timeout_in_ms属性可以设置节点最大响应等待时间,默认为10秒,当一个节点的请求超过这个值,就认为这个节点无响应。
代码实现
读一致性级别的代码实现和写操作基本一致,在这里就不赘述。
调整一致性级别
可用的一致性级别包括ONE、TWO、THREE,分别指定必须响应请求的复制节点的绝对数量。一致性级别QUORUM要求大多数复制节点响应(复制因子/2+1)。一致性级别ALL要求所有副本都响应。对于读写操作,ANY、ONE、TWO、THREE都是弱一致性,QUORUM和ALL是强一致性。经常会用下面的公式来计算强一致性节点数:
R+W>N = 强一致性,在公式中,R、W、N分别代表读副本数、写副本数、复制因子。
比如,我们在集群部署了三个节点,复制因子设置为3。当客户端的一致性级别设置为ONE,集群中即使出现了两个节点宕机,客户端的读写操作依然保持正常,如果两个宕机节点能及时恢复,Cassandra的提示移交(Hinted Handoff) 功能还可以自动将增量数据同步到相应的副本节点。而如果客户端一致性级别设置为QUORUM(3/2+1=2),那么必须有至少2个节点响应才能报告给客户端读写正常。
在两个数据中心集群中,每个数据中心的复制因子为3(意味着6个副本),QUORUM将是4([6/2] + 1 = 4),这意味着如果两个节点出现异常查询仍然可以成功。
这里有一个很有意思的网站,可以根据自己的输入(集群节点数,副本数,读写级别)来做判断自己容忍的节点、数据可靠性等信息。
总结
Cassandra属于无中心集群架构,客户端驱动实现了负载均衡策略,并基于复制因子进行集群复制达到数据冗余。Cassandra为读写提供了不同的一致性级别参数,并且由客户端进行控制,控制粒度可以是全局级别的也可以是单条语句级别的。可以根据具体业务场景在AP和CP之间权衡,使基础设施层服务更健壮。Cassandra内部使用读修复和提示移交机制确保数据的“最终一致性”。可以根据业务场景使用公式“R+W>N = 强一致性”调整一致性级别。

