本篇为译文,原文出自IEEE Xplore学术论文数据库,原文链接:A Big Data Modeling Methodology for Apache Cassandra
在涉及零宕机,线性可伸缩和无缝多数据中心部署的大数据管理方面,Apache Cassandra是领先的首选分布式数据库。随着数百家大型互联网公司越来越多地采用Cassandra进行在线交易处理,越来越需要一种严格而实用的数据建模方法,以确保合理有效的方案设计。 这项工作包括:
- 为Apache Cassandra提出了第一个查询驱动的大数据建模方法
- 定义了重要的数据建模原理,映射规则和映射模式以指导逻辑数据建模
- 给出了Cassandra逻辑和物理数据模型的可视化图
关键词—Apache Cassandra, data modeling, automation, database design, big data, Chebotko Diagrams, CQL
一. 介绍
Apache Cassandra是领先的事务性、可伸缩性和高可用的分布式数据库。它在集群中管理着世界上最大的数据集,在多数据中心中部署了成千上万个节点。 Cassandra数据管理用例包括产品目录和播放列表,传感器数据和物联网,消息传递和社交网络,推荐系统,欺诈检测以及处理时序数据的许多其他应用。 Cassandra在大数据应用中的广泛采用归因于其可伸缩及容错的点对点体系结构,以及从BigTable数据模型演变而来的通用灵活的数据模型。声明式和用户友好的Cassandra查询语言(CQL),以及非常高效的读写访问路径,使关键的大数据应用始终保持运行状态,每秒可扩展至数百万个事务,并轻松处理节点乃至整个数据中心故障。采用Cassandra时,新项目面临的最大挑战之一是与过去使用的传统数据建模方法有显着差异。
关系型数据库中使用的传统数据建模方法定义了数十年的数据库研究形成的完善的步骤。数据库设计人员通常遵循图1(a)中描述的数据库模式设计工作流来定义概念数据模型,将其映射到关系数据模型,范式化关系,并应用各种优化以建立表和索引的有效数据库模式。在此过程中,主要重点在于理解数据并将其组织成关系,最大程度地减少数据冗余并避免数据重复。查询在模式设计中扮演次要角色。由于结构化查询语言(SQL)的表达能力很强,它很容易地支持关系联接,嵌套查询,数据聚合以及许多其他有助于检索存储数据所需子集的功能,在设计的早期阶段常常会省略查询分析。因此,传统的数据建模是一个纯粹的数据驱动过程,其中在数据查询时仅考虑创建索引,并偶尔使用视图来优化频繁执行的查询。

相反,传统数据库设计中使用的方法无法直接应用于Cassandra中的数据建模。首先,Cassandra数据模型旨在为应用程序实现卓越的读写性能。Cassandra的数据建模始于应用程序查询。因此,仅基于概念性数据模型设计Cassandra表而不考虑查询会导致效率低下的查询或数据模型无法支持的查询。其次,CQL不支持SQL中许多常见的构造,包括昂贵的表联接和数据聚合。相反,有效的Cassandra数据库模式设计依赖于数据嵌套或模式反范式化,以使复杂的查询仅通过访问单个表即可满足需求。通常,将相同数据存储在多个Cassandra表中以支持不同的查询,这会导致数据冗余。因此,范式化和最小化数据冗余的传统哲学与Cassandra的数据建模技术完全相反。总而言之,传统的数据库设计不适合开发正确的更不用说高效的Cassandra数据模型。
在本文中,我们为Apache Cassandra提出了一种新颖的查询驱动的数据建模方法。图1(b)显示了我们的方法的流程。 Cassandra解决方案架构师是一个既包含数据库设计又包含应用设计任务的角色,它通过构建概念性数据模型并定义应用的工作流来捕获所有应用程序与数据库的交互,从而开始数据建模。应用程序工作流描述了数据驱动的应用程序需要针对数据库运行的访问模式或查询。基于识别出的访问模式,解决方案架构师将概念数据模型映射成逻辑数据模型。逻辑数据模型形成Cassandra表,这些表可以根据应用程序工作流有效地支持应用的查询。最后,还应用了有关数据类型,键,分区大小和排序的其他物理优化方法,创建CQL在Cassandra中的物理数据模型。

与关系型数据库设计相比,我们方法的最重要创新是,应用程序工作流和访问模式在数据建模过程中成为一等公民。 Cassandra数据库设计围绕应用程序工作流和数据展开,两者都至关重要。与传统策略相比,我们的方法的另一个关键差异是消除了范式化,并且使用数据嵌套来设计逻辑数据模型的表。这也意味着,对于复杂的应用程序查询,表联接被数据冗余和物化视图取代。这些巨大的差异不仅需要对数据建模实践进行调整。他们呼吁一种新的思维方式,从纯粹的数据驱动方法到查询驱动的数据建模过程的转变。
据我们所知,这项工作提出了第一种用于Apache Cassandra的查询驱动的数据建模方法。我们的主要贡献是:
- 用于Apache Cassandra的首创的数据建模方法
- 指导逻辑数据建模过程的一组建模原理,映射规则和映射模式
- 用于逻辑和物理数据模型的可视化技术(称为Chebotko图)
本文的第二部分提供了有关Cassandra数据模型的背景知识。第三部分介绍概念数据建模和应用程序工作流。第四部分详细介绍了从概念数据模型到逻辑数据模型的查询驱动映射。第五部分简要介绍了物理数据建模。第六部分说明了使用Chebotko图来可视化逻辑和物理数据模型。
二.Cassandra数据模型
Cassandra中的数据库模式由一个Key Space(相当于关系型数据库的数据库)表示,在Key Space内,定义了一组表来存储和查询特定应用程序的数据。在本节中,我们讨论Cassandra中使用的表和查询模型。
表模型
Cassandra中表的概念与关系数据库中表的概念不同。 CQL表(以下称为表)可以视为包含一组具有相似结构的行的一组分区。表中的每个分区都具有唯一的分区键(partition key),并且分区中的每行都可以选择唯一的集群键(clustering key)。这两个键可以是简单的(一列)或复合的(多列)。分区键和集群键的组合唯一标识表中的一行,称为主键(primary key)。主键的分区键是必须的,而集群键是可选的。没有集群键的表只能单行分区,因为它的主键等效于分区键,并且分区和行之间存在一对一的映射。具有集群键的表可以有多行分区,因为同一分区中的不同行具有不同的集群键。多行分区中的行始终按集群键值的升序(默认)或降序排列。
一个表定义了一组列和一个主键。每列都有一种数据类型,该数据类型可以是原始数据类型,例如int或text,也可以是复杂的(集合数据类型),例如set,list或map。也可以为列分配特殊的计数器数据类型,该数据类型用于维护分布式计数器,该计数器可以支持并发事务的加/减。在存在计数器列的情况下,表中的所有非计数器列都必须是主键的一部分。可以将列定义为静态列,这仅在具有多行分区的表中有意义,表示其值由分区中的所有行共享的列。最后,主键是由分区键列和可选的集群键列组成的一系列列。在CQL中,分区键列使用括号区分,如果分区键很简单,则可以省略。主键可以不包括计数器,静态或集合列。
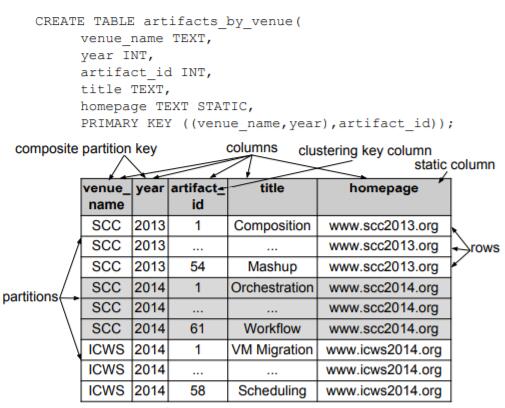
为了说明其中一些概念,图2(a)显示了两个示例表和示例行。 在图2(a)中,Artifacts表包含单行分区。 它的主键由一个列artifact_id组成,它也是一个简单的分区键。 该表显示为有三个单行分区,也就是每行属于一个分区。

在图2(b)中,artifacts_by_venue表包含多行分区。 它的主键由复合分区键(venue name, year)和简单的集群键artifact_id组成。该表显示有三个分区,每个分区包含多行。对于任何给定的分区,其行按artifact_id升序排列。另外,homepage定义为静态列,因此每个分区只能有一个homepage值,该值由该分区中的所有行共享。
查询模型
对表的查询用CQL表示,它有类似SQL的语法。与SQL不同,CQL不支持表联接之类的操作,并且有许多用于确保效率和可伸缩性的查询规则:
- 查询谓语(谓语是用逻辑运算符 AND 和 OR 连接在一起的条件表达式,可在 WHERE、HAVING 或 ON 子句中组成条件集合)中只能使用主键列。
- 所有分区键列必须受限于值(比如相等查询条件)。
- 可以在查询谓词中使用全部、部分或不包含任何集群键列。
- 如果在查询条件中使用了集群键列,则在谓词中也必须使用主键定义中此集群列之前的所有集群键列。
- 如果查询谓词中的集群键列受到范围(比如不相等搜索)的限制,则主键定义中此集群键列之前的所有集群键列都必须受到值的限制,谓词中不能使用其他集群列。
直观地,按值限制所有分区键列的查询将返回由指定分区键标识的分区中的所有行。 例如,以下对图2(b)中的查询将返回在场所SCC 2013中发布的所有中Artifacts:
1 | SELECT artifact_id, title FROM artifacts_by_venue WHERE venue_name='SCC' AND year=2013 |
通过值限制所有分区键列和某些集群键列的查询将返回分区中满足该谓词的行的子集。类似地,查询按值限制所有分区键列,并按范围限制一个集群键列,它从分区中返回满足该谓词的行的子集。例如,以下针对图2(b)中的查询将返回ID为1到20的Artifact(在SCC 2013中发布)
1 | SELECT artifact_id, title FROM artifacts_by_venue WHERE venue_name='SCC' AND year=2013 AND artifact_id>=1 AND artifact_id<=20 |
定义表时,查询结果始终根据为集群键列指定的默认顺序进行排序,除非查询明确指定顺序(ORDER BY)。
最后,CQL支持许多其他功能,例如使用二级索引,IN和ALLOW FILTERING语法的查询。 我们的数据建模方法并不直接依赖于此类查询,因为在大数据场景下,它们的性能通常是不可预测的。
三. 概念数据建模和工作流建模
方法的第一步是为数据库设计增加一个全新的维度,这在传统的关系方法中是看不到的。设计Cassandra数据库模式不仅需要了解要管理的数据,还需要了解数据驱动的应用程序如何访问此类数据。前者是通过概念数据模型(例如实体关系模型)获得的。特别是,我们选择使用实体关系图进行概念数据建模,因为这种表示法与技术无关,并且不带有任何关系模型特征。后者是通过应用程序工作流图获得的,该图定义了各个应用程序事件的数据访问模式。每个访问模式都指定要使用分布式计数器搜索,排序或进行聚合的字段。为了提高可读性。
作为示例,我们为数字图书馆设计了一个数据库。该数字图书馆收藏了各种数字工件,例如论文,这些工件在各个场所发表。注册用户可以以评论、点赞和评分的形式对场地和工件留下反馈。图3显示了我们的示例的概念数据模型和应用程序工作流。图3(a)中的概念数据模型明确定义了所有已知的实体类型,关系类型,字段类型,主键,和其他约束。例如,该图的一部分可以解释为“用户由ID唯一标识,并且可以发布许多评论,而每个评论有且唯一由一个用户发布的”。
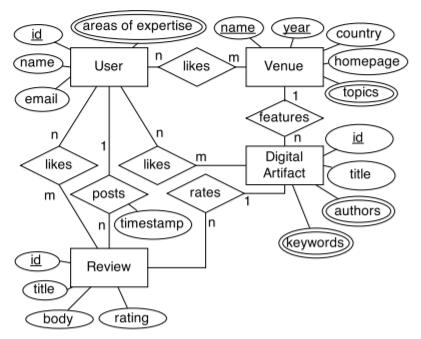
图3(b)中的应用程序工作流对基于Web的应用程序进行了建模,该应用程序允许用户与各种网页(任务)进行交互,使用定义明确的查询来检索数据。例如,图中的最上层的任务是应用程序的入口点,并允许基于不同字段的查询在数据库中搜索工件。正如我们在下一节中显示的那样,概念数据模型和应用程序工作流程都对逻辑数据模型的设计产生深远影响。
四. 逻辑建模
Cassandra数据建模方法的关键是逻辑数据建模。它使用上面概念数据模型作为输入物,并根据应用程序工作流中定义的查询将其映射到逻辑数据模型。逻辑数据模型对应于Cassandra数据库模式,其中表模式定义了列,主键,分区键和集群键。我们通过数据建模原理,映射规则和映射模式定义了查询驱动的概念到逻辑数据模型映射。
数据建模原则
以下四个数据建模原则为概念到逻辑数据模型的映射提供了基础:
理解数据
成功进行数据库设计的第一个关键是理解数据,这些数据是用概念数据模型获得的。不应低估概念数据建模的重要性。ER图上的实体,关系和字段类型(例如,参见图3(a))不仅定义了哪些数据需要存储在数据库中,还定义了哪些数据字段(例如实体类型和关系类型关键字),需要保留并依靠它来正确地组织数据。
例如,在图3(a)中,名称和年份构成场所的主键。 这是基于我们的用例假设,即在同一年内不能有两个名称相同的场所(例如会议)。如果我们的假设是错误的,那么概念数据模型和总体设计将不得不改变。另一个示例是关系类型特征的基数。在这种情况下,我们的用例假设一个场所可以包含许多工件,而一个工件只能出现在一个场所中。 因此,给定一对多关系类型,特征的关键是工件的id。同样,如果我们的假设是错误的,则基数和主键都将必须更改,从而导致表模式设计大不相同。
理解查询
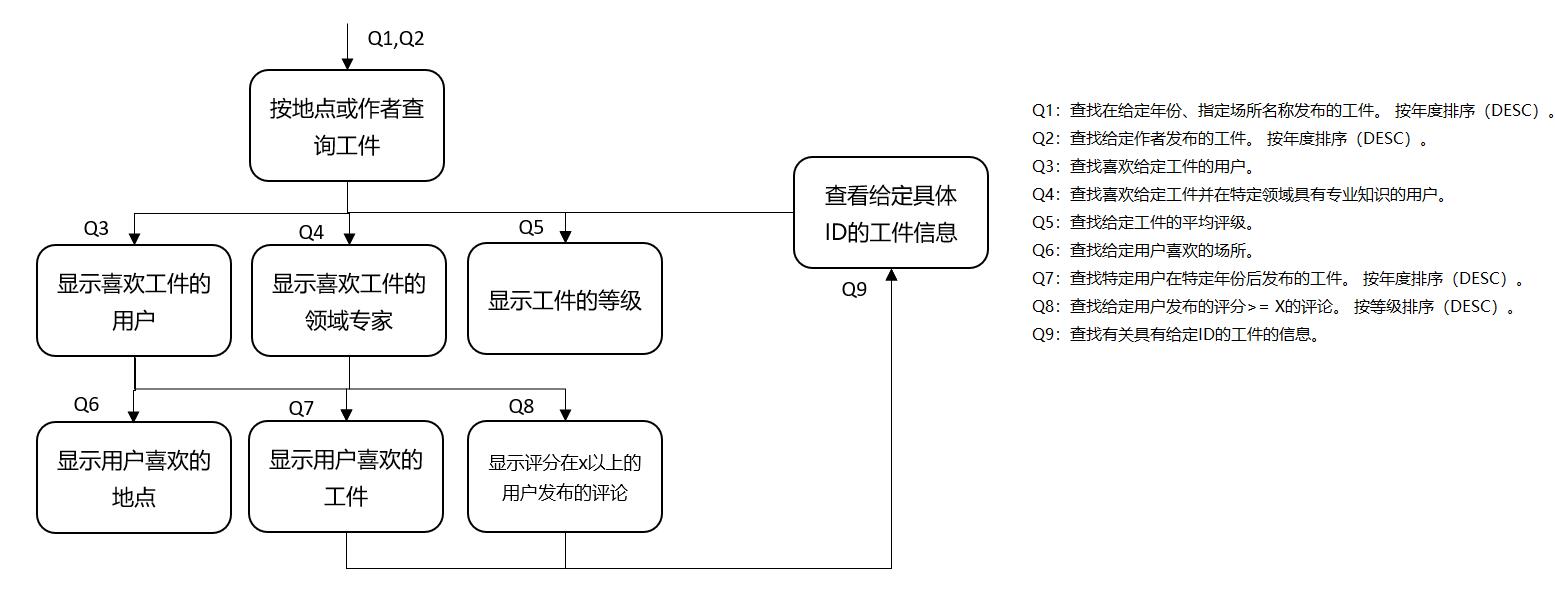
成功数据库设计的第二个关键是查询,这些查询是通过应用程序工作流模型捕获的。就像数据一样,查询会直接影响表模式的设计,并且如果我们对查询的用例假设(例如,参见图3(b))发生变化,那么数据库模式也将发生变化。除了考虑查询,我们还应考虑每个查询的访问路径以有效地组织数据。
我们定义了三种宽泛的访问路径:1)单分区查询,2)多分区查询,以及3)多表查询。 最有效的选项是“单分区查询”,当查询仅从单个分区中检索一行,一部分行或所有行时。 例如,第二部分中介绍的两个查询都是“每个查询分区”访问路径的示例。该访问路径应该是在线事务处理场景中最常见的路径,但是在某些情况下可能是不可能或不希望的(例如,分区可能必须变得很大才能满足此查询路径)。“多分区查询”和“多表查询”路径分别是指从表中的几个分区或一个或多个表中的多个分区中检索数据。 尽管这些访问路径在某些情况下可能是有效的,但应避免使用它们以实现最佳查询性能。
数据嵌套
成功的数据库设计的第三个关键是数据嵌套。数据嵌套是指一种基于已知准则将多个实体(通常是同一类型)组织在一起的技术。这样的标准可以是,所有嵌套实体的某些属性必须具有相同的值(例如,具有相同名称的场所),或者所有嵌套实体必须与不同类型的已知实体相关(例如,特定场所)。数据嵌套用于实现“单分区查询”访问路径,以便可以从单个分区中检索多个嵌套实体。 Cassandra中有两种嵌套数据的机制:多行分区和集合类型。我们的方法主要依靠多行分区来获得最佳性能。例如,在图2(b)中,将工件(行)嵌套在以这些工件为特征的场所(分区)下。换句话说,每个分区对应于一个场所,给定分区中的每一行对应于出现在该分区场所中的工件。多行分区的表在Cassandra数据库中很常见。
数据复制
成功的数据库设计的第四个关键是数据复制。跨多个表,分区和行在Cassandra中复制数据是一种常见做法,需要有效地支持对同一数据的不同查询。复制数据以启用“单分区查询”访问路径要比从多个表和分区联接数据要好得多。例如,为了通过有效的“单分区查询”访问路径来支持图3(b)中的查询Q1和Q2,我们应该创建两个单独的表,这些表使用不同的表主键来组织同一组工件。 在Cassandra中,空间效率和时间效率之间的权衡几乎总是选择后者。
映射规则
基于上述数据建模原则,我们定义了五个映射规则,这些规则指导了查询驱动的从概念数据模型到逻辑数据模型的过渡。
实体和关系
实体和关系类型映射到表,而实体和关系映射到行。在概念级别描述实体和关系的属性类型必须在逻辑级别保留为列。违反此规则可能会导致数据丢失。
相等查询字段
在查询谓词中使用的相等查询字段映射到表主键的前缀列。此类列必须包括所有分区键列,以及(可选)一个或多个集群键列。违反此规则可能导致无法支持查询要求。
不相等查询字段
查询谓词中使用的不相等查询字段映射到表集群键列。在主键定义中,参与不相等查询的列必须紧跟参与相等查询的列。违反此规则可能导致无法支持查询要求。
排序字段
在查询中指定的排序字段按查询所指定的升序或降序映射到集群键列。违反此规则可能导致无法支持查询要求。
主键字段
主键字段类型映射到主键列。将实体或关系存储为行的表必须包括主键字段,这些主键字段作为表主键的一部分来唯一标识这些实体或关系,以唯一地标识行。违反此规则可能会导致数据丢失。
要设计表模式,将这些映射规则应用于特定查询和该查询要处理的概念数据模型的子图的上下文中很重要。 规则应按照上面列出的顺序应用。
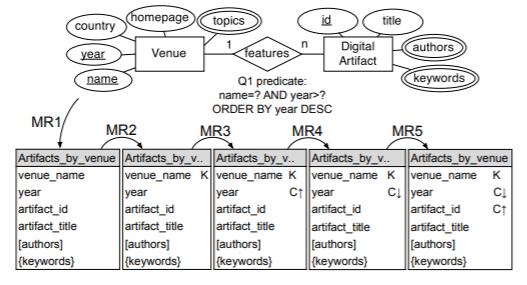
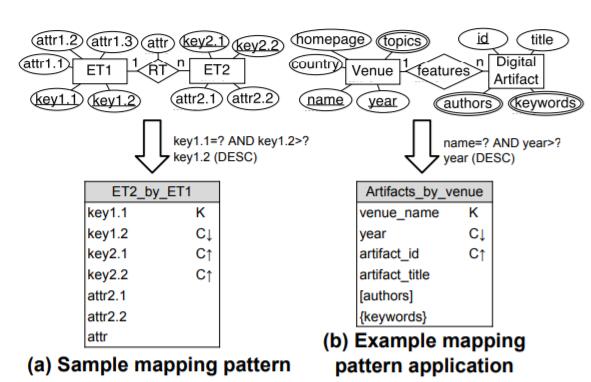
例如,图4解释了如何将映射规则应用于设计用于查询Q1的表(参见图3(b)),该表处理场所-特征-数字工件(参见图3(a))的关系。 图4直观地显示了每个规则应用后使用Chebotko的符号表示的表格,其中K和C分别表示分区和集群键列。 集群键列旁边的箭头表示升序(↑)或降序(↓)。规则1在按场所生成的工件表中,其列与查询中用于搜索,搜索或排序的字段类型相对应。规则2将相等性查询字段映射到分区键列场所名称。规则3将不相等搜索字段映射到集群键列年份,而规则4将集群键顺序更改为降序。 最后,规则5将主键字段映射到集群键列artifact_id。
映射模式
基于上述映射规则,我们设计映射模式,这些映射模式是自动执行Cassandra数据库架构设计的基础。 给定查询和与查询相关的概念性数据模型子图,每种映射模式都可以定义最终表模式设计,而无需应用单独的映射规则。尽管我们定义了许多不同的映射模式,但由于篇幅所限,我们仅介绍一种映射模式和一个示例。
在图5(a)中解释了映射模式。当给定查询处理一对多关系并导致根据该关系在一个实体(分区)下嵌套许多实体(行)的表模式时,它是适用的。 当应用于查询Q1(请参见图3(b))和“场地特征-数字工件”关系(请参见图3(a))时,此映射模式将形成图5(b)所示的表模式。 使用我们的映射模式,逻辑数据建模变得很简单,并且可以自动进行。
五. 物理数据建模
我们方法论的最后一步是分析和优化逻辑数据模型来创建物理数据模型。尽管建模原理,映射规则和映射模式可确保正确且有效的逻辑架构,但还有其他与数据库引擎约束或有限的集群资源有关的效率问题。逻辑数据模型的典型分析涉及表分区大小和数据复制因子的估算。一些常见的优化技术包括分区拆分,反向索引,数据聚合和并发数据访问优化。
六. Chebotko图
为实现可视化呈现逻辑和物理数据模型设计,我们提出了一种新颖的可视化技术,称为Chebotko图,它将数据库模式设计为单个表模式和查询驱动的应用程序工作流转换的组合。与常规CQL模式定义脚本相比,Chebotko图的优点包括:改进了整体可读性、复杂数据模型的可理解性,以及更好的表达性,这些特性包括表模式和支持的应用程序查询。物理级别的图包含足够的信息,可以自动生成CQL脚本,并且可以用作设计和维护数据驱动的参考文档。 Chebotko图的表示法如图6所示。
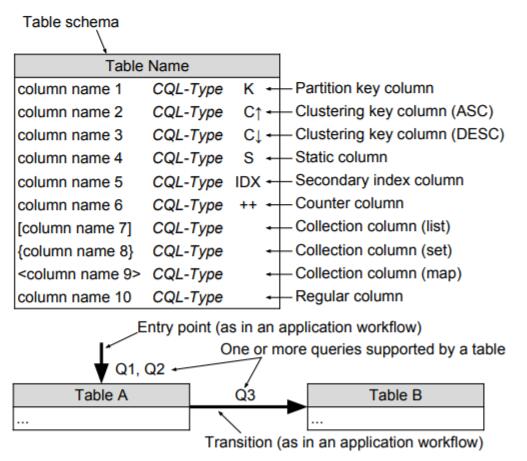
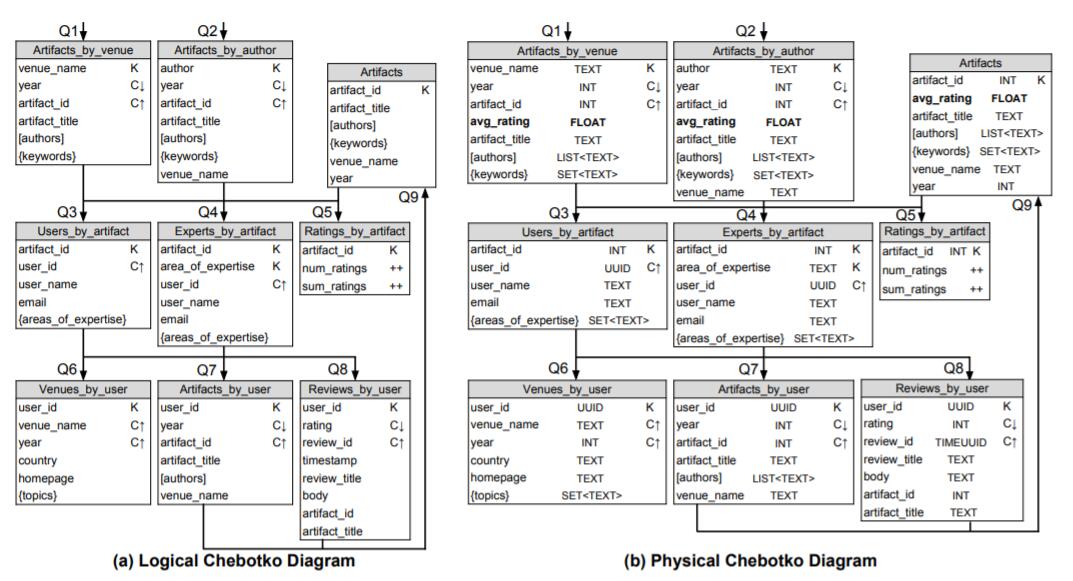
图7中显示了数字图书馆示例Chebotko图。图7(a)中的逻辑视图是使用映射规则和映射模式从图3中的概念数据模型和应用程序工作流派生的。在为所有列指定CQL数据类型并进行两个较小的优化之后,图7(b)中的物理视图是从逻辑数据模型得出的:
- 将新列【avg_rating】添加到表Artifacts_by_venue,
Artifacts_by_author和Artifacts表中,避免额外查询Rating_by_artifact表。 - 从Reviews_by_user表中删除了timestamp列,因为可以从TIMEUUID类型的列review_id中提取时间戳。
七. 总结
在本文中,我们为Apache Cassandra引入了严格的查询驱动的数据建模方法。事实证明,我们的方法在许多方面与传统的关系数据建模方法完全不同,例如查询驱动的模式设计,数据嵌套和数据复制。我们详细介绍了Cassandra的基本数据建模原理,并定义了映射规则和映射模式,以从与技术无关的概念数据模型过渡到特定于Cassandra的逻辑数据模型。我们还解释了物理数据建模的作用,并提出了一种新颖的可视化技术,称为Chebotko图,可用于描述复杂的逻辑和物理数据模型。

